This post is part of a series of posts to analyze the digital me.
Visualize and analyse IMDB ratings with R
In my previous post in this series I shared how I collect and store my personal ratings data from IMDB and enrich it with a few important variables about the movie.
In this post I will explore the data to learn about my movie preferences. I will be using some R packages to structure the data properly and other packages to build plots:
I’m sure my code can be optimized to use less packages or run faster in general. Feel free to reach out to me if you have suggestions on how to do this. I’m learning as I’m going.
Load data.frame with IMDB rating data
I have loaded my data.frame with my ratings, IMDB ratings and general movie info to analyse. You can see how I collected this data in my previous post.
head(data_imdb)## X id title year
## 1 1 tt0054047 The Magnificent Seven 1960
## 2 2 tt0060196 Il buono, il brutto, il cattivo 1966
## 3 3 tt0066999 Dirty Harry 1971
## 4 4 tt0068646 The Godfather 1972
## 5 5 tt0071562 The Godfather: Part II 1974
## 6 6 tt0072890 Dog Day Afternoon 1975
## description
## 1 An oppressed Mexican peasant village hires seven gunfighters to help defend their homes.
## 2 A bounty hunting scam joins two men in an uneasy alliance against a third in a race to find a fortune in gold buried in a remote cemetery.
## 3 When a mad man calling himself 'the Scorpio Killer' menaces the city, tough as nails San Francisco Police Inspector Harry Callahan is assigned to track down and ferret out the crazed psychopath.
## 4 The aging patriarch of an organized crime dynasty transfers control of his clandestine empire to his reluctant son.
## 5 The early life and career of Vito Corleone in 1920s New York City is portrayed, while his son, Michael, expands and tightens his grip on the family crime syndicate.
## 6 A man robs a bank to pay for his lover's operation; it turns into a hostage situation and a media circus.
## myRating url type imdb_rating
## 1 7 http://www.imdb.com/title/tt0054047/?ref_=rt_li_tt Movie 7.8
## 2 9 http://www.imdb.com/title/tt0060196/?ref_=rt_li_tt Movie 8.9
## 3 8 http://www.imdb.com/title/tt0066999/?ref_=rt_li_tt Movie 7.8
## 4 10 http://www.imdb.com/title/tt0068646/?ref_=rt_li_tt Movie 9.2
## 5 9 http://www.imdb.com/title/tt0071562/?ref_=rt_li_tt Movie 9.0
## 6 8 http://www.imdb.com/title/tt0072890/?ref_=rt_li_tt Movie 8.0
## imdb_ratings imdb_director
## 1 78141 John Sturges
## 2 592879 Sergio Leone
## 3 127937 Don Siegel
## 4 1370383 Francis Ford Coppola
## 5 948713 Francis Ford Coppola
## 6 212269 Sidney Lumet
## imdb_cast
## 1 Yul Brynner|Eli Wallach|Steve McQueen|Horst Buchholz|Charles Bronson|Robert Vaughn|Brad Dexter|James Coburn|Jorge Martínez de Hoyos|Vladimir Sokoloff|Rosenda Monteros|Rico Alaniz|Pepe Hern|Natividad Vacío|Mario Navarro
## 2 Eli Wallach|Clint Eastwood|Lee Van Cleef|Aldo Giuffrè|Luigi Pistilli|Rada Rassimov|Enzo Petito|Claudio Scarchilli|John Bartha|Livio Lorenzon|Antonio Casale|Sandro Scarchilli|Benito Stefanelli|Angelo Novi|Antonio Casas
## 3 Clint Eastwood|Harry Guardino|Reni Santoni|John Vernon|Andrew Robinson|John Larch|John Mitchum|Mae Mercer|Lyn Edgington|Ruth Kobart|Woodrow Parfrey|Josef Sommer|William Paterson|James Nolan|Maurice Argent
## 4 Marlon Brando|Al Pacino|James Caan|Richard S. Castellano|Robert Duvall|Sterling Hayden|John Marley|Richard Conte|Al Lettieri|Diane Keaton|Abe Vigoda|Talia Shire|Gianni Russo|John Cazale|Rudy Bond
## 5 Al Pacino|Robert Duvall|Diane Keaton|Robert De Niro|John Cazale|Talia Shire|Lee Strasberg|Michael V. Gazzo|G.D. Spradlin|Richard Bright|Gastone Moschin|Tom Rosqui|Bruno Kirby|Frank Sivero|Francesca De Sapio
## 6 Penelope Allen|Sully Boyar|John Cazale|Beulah Garrick|Carol Kane|Sandra Kazan|Marcia Jean Kurtz|Amy Levitt|John Marriott|Estelle Omens|Al Pacino|Gary Springer|James Broderick|Charles Durning|Carmine Foresta
## imdb_genres imdb_time date imdb_release_date
## 1 Action|Adventure|Western 128 2018-10-02 <NA>
## 2 Western 161 2018-10-02 <NA>
## 3 Action|Crime|Thriller 102 2018-10-02 <NA>
## 4 Crime|Drama 175 2018-10-02 <NA>
## 5 Crime|Drama 202 2018-10-02 <NA>
## 6 Biography|Crime|Drama|Thriller 125 2018-10-02 <NA>Let’s first get some summary data to see what is in my data.frame.
#Number of movies in dataframe
nrow(data_imdb)## [1] 837# Average IMDB from all users on movies
round(mean(data_imdb$imdb_rating),2)## [1] 6.89#Average rating from me on the same movies
round(mean(data_imdb$myRating),2)## [1] 6.58What we can immediately see is that I’m not easy to please. My average rating is a lot lower than the one from other IMDB raters.
#My personal top 10 of movies I've rated
head(arrange(data_imdb[,c("title", "myRating")],desc(myRating)),10)## title myRating
## 1 The Godfather 10
## 2 The Wire 10
## 3 Il buono, il brutto, il cattivo 9
## 4 The Godfather: Part II 9
## 5 Taxi Driver 9
## 6 Apocalypse Now 9
## 7 Full Metal Jacket 9
## 8 Goodfellas 9
## 9 The Silence of the Lambs 9
## 10 Reservoir Dogs 9#IMDB users top 10 of movies I've rated
head(arrange(data_imdb[,c("title", "imdb_rating")],desc(imdb_rating)),10)## title imdb_rating
## 1 Band of Brothers 9.5
## 2 The Shawshank Redemption 9.3
## 3 The Wire 9.3
## 4 The Godfather 9.2
## 5 The Godfather: Part II 9.0
## 6 The Dark Knight 9.0
## 7 Il buono, il brutto, il cattivo 8.9
## 8 Schindler's List 8.9
## 9 Friends 8.9
## 10 The Lord of the Rings: The Return of the King 8.9From the looks of the top10’s my taste isn’t totally aligned with the IMDB crowd either. A lot of my favorites are not in the IMDB list.
Comparing my ratings to those of all IMDB users
Let’s dive into those differences a bit more. In order to do this I will create an additional column in my dataframe to show the differences in ratings per movie. I will use the data to show a top10 of biggest positive difference in ratings (I like them a lot more than IMDB users) and the other way around (movies I don’t really like that IMDB users do).
data_imdb$dif_rating <- data_imdb$myRating - data_imdb$imdb_rating
#Biggest differences I like a lot more than IMDB users
head(arrange(data_imdb[,c("title", "dif_rating")],desc(dif_rating)),10)## title dif_rating
## 1 Hobo with a Shotgun 1.9
## 2 Varsity Blues 1.5
## 3 Child of God 1.5
## 4 The Recruit 1.4
## 5 Thank You for Smoking 1.4
## 6 50/50 1.3
## 7 Detachment 1.3
## 8 Birdman or (The Unexpected Virtue of Ignorance) 1.3
## 9 Winged Creatures 1.3
## 10 Surfer, Dude 1.3#Biggest differences IMDB users like a lot more than I do
tail(arrange(data_imdb[,c("title", "dif_rating")],desc(dif_rating)),10)## title dif_rating
## 828 Rookie Blue -2.7
## 829 Arrow -2.7
## 830 Step Brothers -2.9
## 831 Thor -3.0
## 832 Thor: The Dark World -3.0
## 833 Looper -3.4
## 834 The Walking Dead -3.4
## 835 Everwood -3.5
## 836 The Expendables 2 -3.6
## 837 13 -4.1Clearly I don’t get the appeal of the Thor movies, The Expandables 2 and 13, but I somehow thought Hobo with a shotgun was a masterpiece when nobody else seemed to get that movie.
Ratings per decade of movies
I want to learn more about my general preferences, not on an individual movie level, but grouped into segments. Am I a big fan of movies from a particular decade?
Number of movies I watched from each decade
I’m visualising this data with the ggplot2 package. A simple way to make graphs and plots based on dataframes. There a lots of resources about this package to learn how it works.
theme_data <- theme_light(base_size = 13) + theme(plot.margin=unit(c(0.5,1,1.5,1.2),"cm"))
color_bar <- "#999999"
color_fill <- "#5c85d6"
#spread of movie release decades
(data_imdb$year %/% 10) * 10 -> data_imdb$decade
ggplot(data = data_imdb, aes(x = decade))+
geom_bar(stat = 'count', fill=color_fill, color = color_bar) +
scale_x_continuous(breaks = c(1930, 1940, 1950, 1960, 1970, 1980, 1990, 2000, 2010)) +
scale_y_continuous(expand = c(0, 0),breaks = seq(0, 325, 25), limits = c(0,325)) +
geom_text(stat='count',aes(label=..count..),vjust=-0.5) +
ylab("Number of movies watched") +
theme_data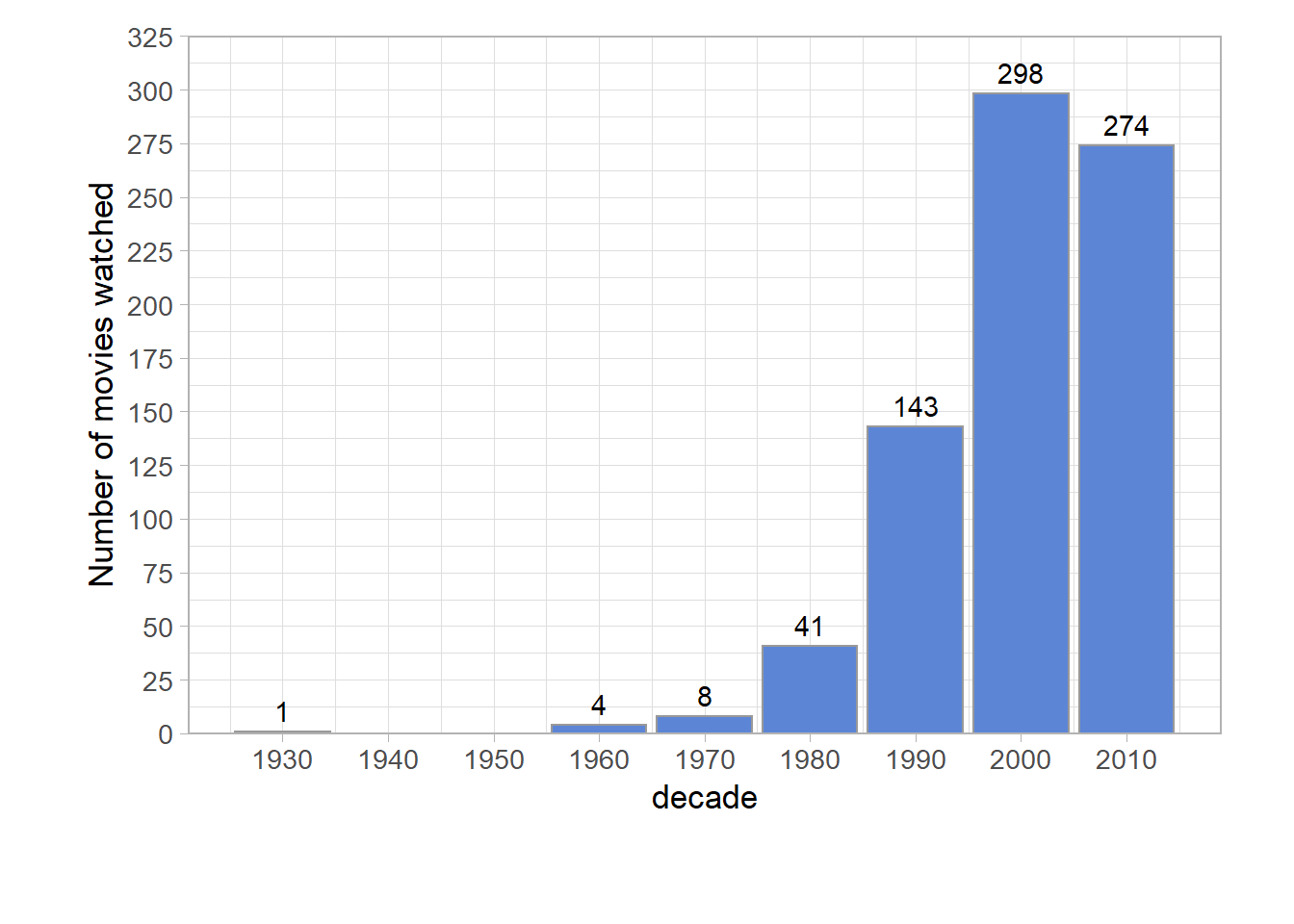 Most of the movies I have reviewed are from the past 20 years. I still have to rate my first forties of fifties movie on IMDB…
Most of the movies I have reviewed are from the past 20 years. I still have to rate my first forties of fifties movie on IMDB…
My ratings of movies per decade
ggplot(data = data_imdb, aes(x = decade, y = myRating))+
geom_bar(stat = "summary", fun = "mean", fill = color_fill, color = color_bar) +
ylab("Average rating") +
theme_data +
scale_x_continuous(breaks = c(1930, 1940, 1950, 1960, 1970, 1980, 1990, 2000, 2010)) +
scale_y_continuous(limits = c(0,10), breaks = c(0:10)) +
stat_summary(aes(label=round(..y..,2)), fun.y=mean, geom="text", vjust = -0.75)
Difference in ratings between me and all IMDB users
ggplot(data = data_imdb, aes(x = decade, y = dif_rating))+
geom_bar(stat = "summary", fun = "mean", fill=color_fill, color = color_bar)+
ylab("Difference in average rating") +
theme_data +
stat_summary(aes(label=round(..y..,2)), fun=mean, geom="text", vjust = -0.75) +
scale_y_continuous(limits = c(-2,2), breaks = c(-2,-1,0,1,2))
It turns out I’m not giving very high ratings in comparison to all IMDB users, regardless of the decade the movie is from. Based on my ratings per decade and the difference between me and IMDB users, it would make sense to enjoy some more movies from the nineties and older than the nineties. I’m really tough on movies from the past 20 years in comparison to other IMDB raters (-0.37 and -0.43).
On the other hand, I’m watching a lot of movies that were released in the past 20 years. Maybe I should just pick them more carefully. Let’s find out if there is a bigger range of ratings I give to movies from the past 20 years than other years.
Distribution of my ratings per decade
I will be using a boxplot to visualise the distribution of my ratings per decade. If you are not sure how to read a boxplot, this is a great explanation about reading boxplots for you to check out.
ggplot(data_imdb, aes(x = decade, y = myRating, group = decade)) +
geom_boxplot() +
ylab("My average rating") +
scale_x_discrete(limit = c(1930, 1940, 1950, 1960, 1970, 1980, 1990, 2000, 2010)) +
theme_data The boxplots can be a little oddly shaped, because I can only rate with whole values (only 7 or 8, not 7.5). A full quartile can consist of one value (ie 6 or 7). The median can also be the same value as the upper quartile or lower quartile.
The boxplots can be a little oddly shaped, because I can only rate with whole values (only 7 or 8, not 7.5). A full quartile can consist of one value (ie 6 or 7). The median can also be the same value as the upper quartile or lower quartile.
In this boxplot there are not a lot of outliers for the past 20 years. This means I’m consistently watching movies that I rate 6 or 7 stars. It is a lot more positive for the eighties and nineties. I’m also rating movies from those times with lower stars, but that isn’t as common. I guess I should be watching more movies older than 20 years.
In my next post I will analyse this dataframe further. I still have to learn more about my favorite actors, directors and genres. I hope to get some good recommendations out of this for movie night.